TLDR
The study introduces a method that employs LLMs for zero-shot and few-shot classification of tabular data by serializing the data into natural-language strings. This approach not only simplifies the process but also demonstrates superior performance over traditional deep-learning and gradient-boosted tree methods in various benchmarks. Particularly, in the few-shot learning scenario, this method shows promising improvements in predictive performance.
Technical
The core of their methodology involves the conversion of tabular data into a format understandable by LLMs—natural language strings. This serialization process, coupled with a brief description of the classification problem, prepares the data for processing by LLMs without prior training specifically on tabular data. They explored several serialization techniques, including templates and table-to-text models, to identify the most effective method. Their experiments utilized the T0 language model and GPT-3, leveraging their inherent understanding of natural language to classify tabular datasets accurately.
In the few-shot setting, they fine-tuned the LLM using a subset of labeled examples through a parameter-efficient method known as T-Few. This approach allowed us to adapt the LLM’s parameters specifically for their classification tasks, improving accuracy with minimal data.
We first serialize the feature names and values into a natural language string. They evaluate different strategies. This string is then combined with a task-specific prompt. To get predictions, we obtain output probabilities from the LLM for each of a pre-specified set of verbalizer tokens (e.g., “Yes”, “No”), which map to class labels (e.g., 1, −1). If 𝑘 > 0, they use the 𝑘 labeled examples to fine-tune the large language model using T-Few (Liu et al., 2022). Finally, they use the (possibly tuned) large language model to obtain predictions on unlabeled examples. The example prompt is shown in Figure 2.


Experiment
Figure 3. shows the average AUC and SD of different serializations across nine public datasets. The Text Template serialization performed very well across all experiments. In the zero-shot setting, the Text Template showed improvements over List Template, indicating the benefit of a serialization that is closer to the training distribution of T0. However, these differences al- ready vanished for 8 training examples. Hence, very few training examples might already suffice to adjust for dif- ferent templates. This suggests that sophisticated serializa- tions might be unnecessary when some training data exists. An interesting finding is that LLM for serialization performs worse than the simple text template based method, as the LLM can have hallucination, which introduces noise into the training data. Using only feature values had a poor performance for zero and very few shots, but the performance equalized with more training examples.
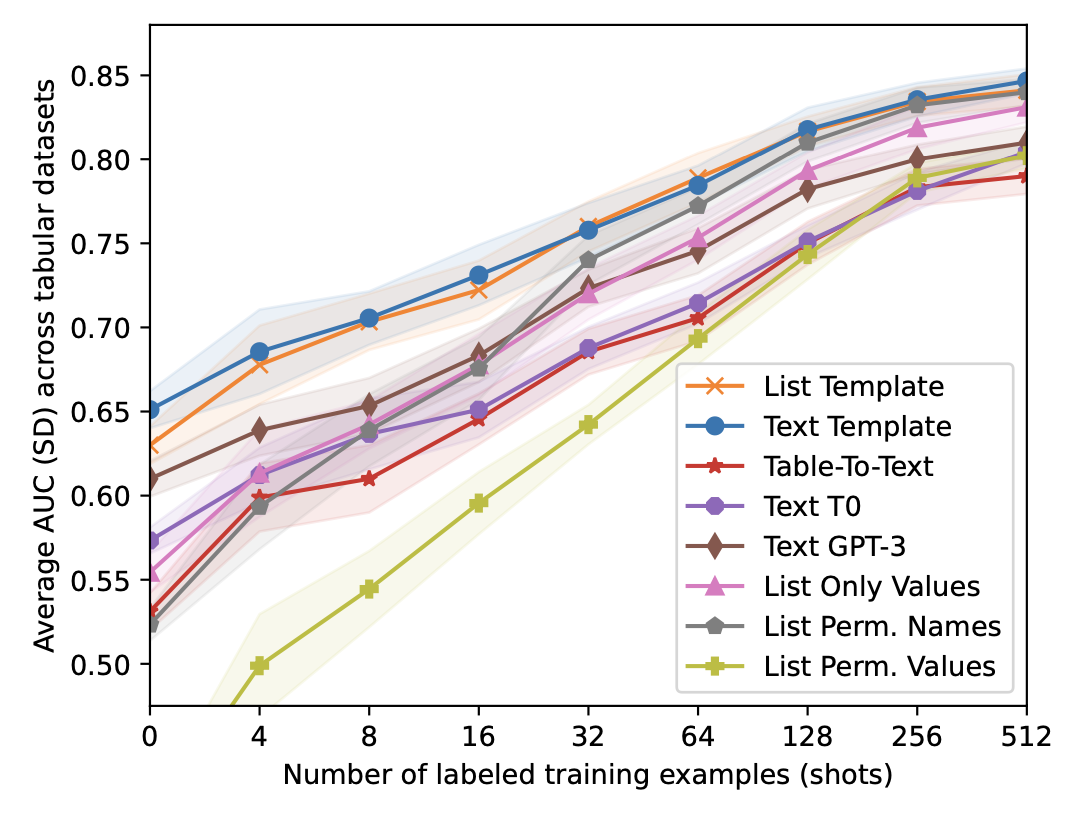
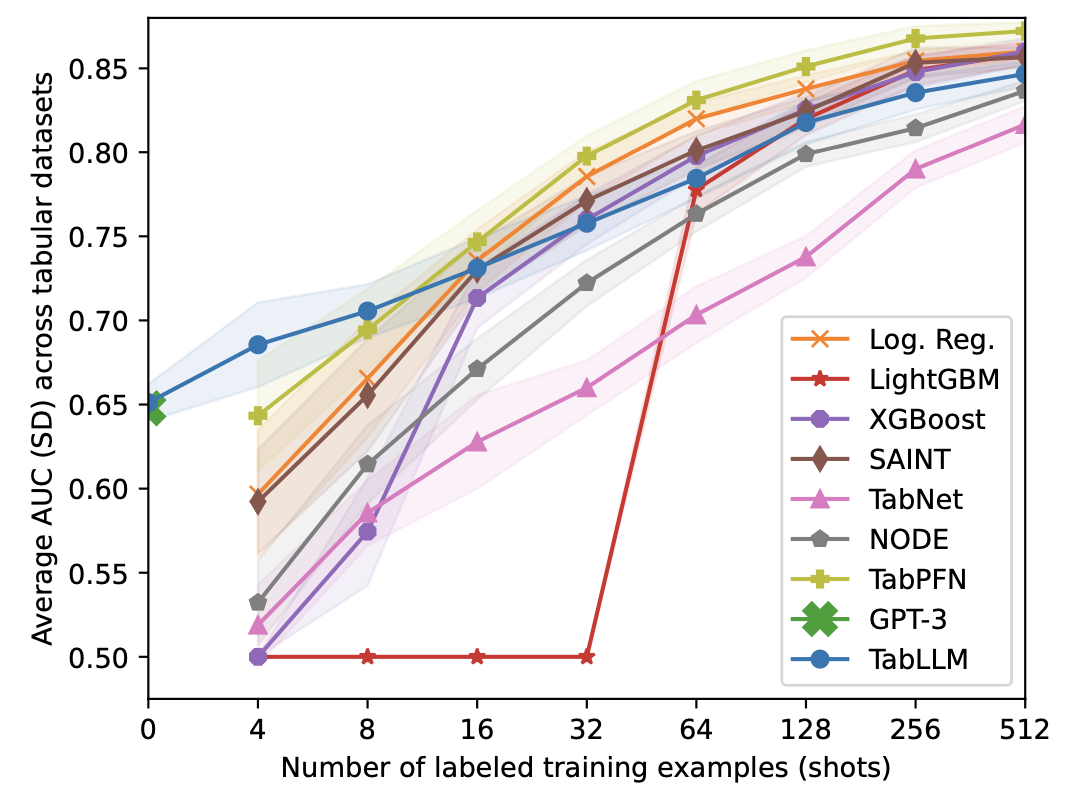
Figure 4 shows the average AUC and SD of TabLLM versus all baseline models across nine public datasets. In all cases, TabLLM’s performance improved with a higher number of shots. In the zero-shot setting, TabLLM was on par with GPT-3 even though GPT-3 is a much larger model than T0 (175B vs. 11B parame- ters). TabPFN consistently outperformed the other baseline models across all numbers of training examples. TabPFN reached TabLLM’s performance with 4 to 256 (Income) training examples. LR was the second-best baseline of- ten beating the tree models, which might be due to our ex- tensive parameter tuning (see Sec. 4 in the Supplement). TabLLM outperformed or was on par with the tree ensem- ble baselines until 256 training examples for all datasets except Calhousing and Jungle. For fewer shots, it often outperformed them by a large margin. XGBoost performed relatively poorly for few shots, which was probably due to overfitting on the small training and validation sets (as de- scribed in the previous section, we do not use large valida- tion sets for hyperparameter tuning to ensure the results are truly few-shot).